
Mapeo Selectivo y Xpath
Tendremos que revisar la página anterior y esta para completar una nueva página sobre XPath que está pendiene en la antigua Dokuwiki. De momento añado la explicación hecha por Estrella de como crear un XPath.
Vamos a ver un concepto muy utilizado en TAST.
Mapeo XPath
Cuando se trabaja con una herramienta de automatización, como es TAST, es muy importante poder identificar objetos y trabajar con ellos. De lo contrario, la herramienta de automatización no sabrá dónde navegar, consultar, buscar, etc. Con XPath definiremos criterios de búsqueda avanzada y eficaz en un documento XML o en una página web.
El XPath que se escribe tiene que ser único y representa solamente un elemento.
Con estos elementos que vamos a ver a continuación, se puede mapear una aplicación completa.
El Xpath normalmente tiene esta forma:
Xpath= //tagname[@atributo=’valor’]
// -> nodo actual.
Los nodos son cada una de esas flechas negras que aparecen ![]() .
.
Si ponemos dos barras no se especifica ningún nivel, sería cualquiera nodo, y como se puede observar hay muchísimos nodos.
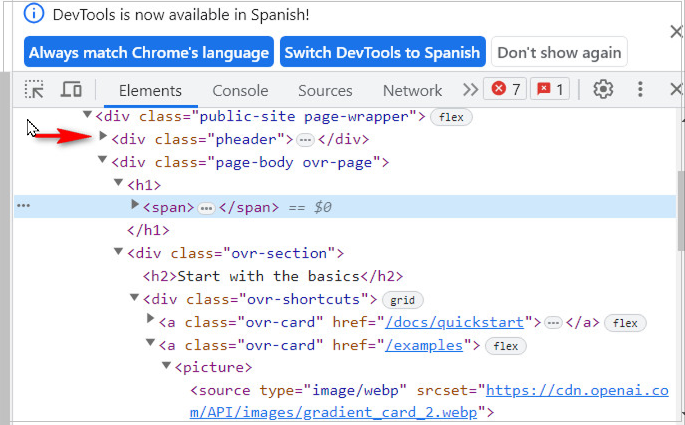
Tagname -> son los que vienen en color lila (en el buscador Chrome).
<div
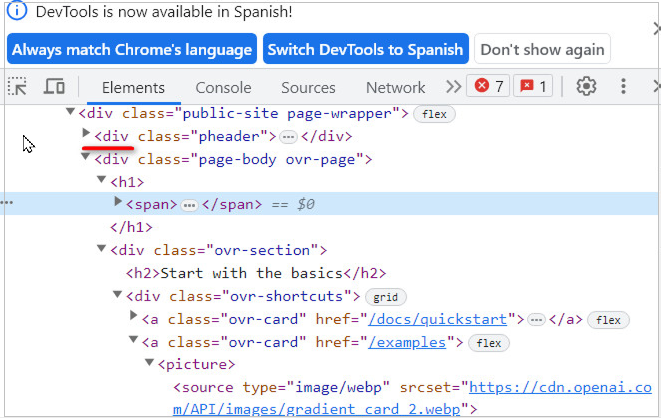
Luego se abre corchete [ y a continuación @
@ -> selecciona un atributo o elemento. Puede ser id, class, type, name value,... Estos vienen en color marrón (en el buscador Chrome).
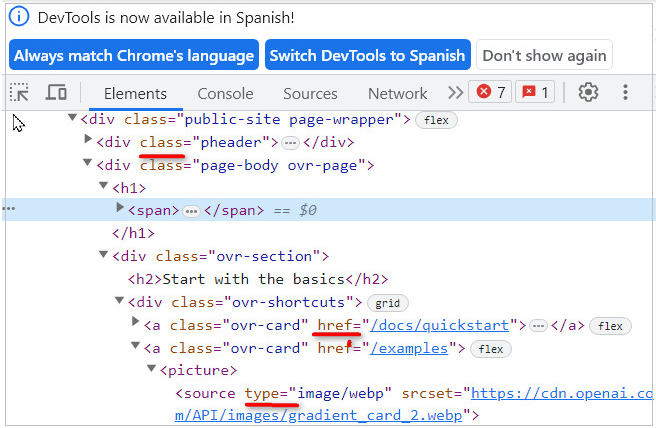
Seguidamente el signo = o contains según lo que quieras
Por último el valor, que se puede poner con comilla simple o comillas dobles.
‘ y “ -> valor del atributo o elemento
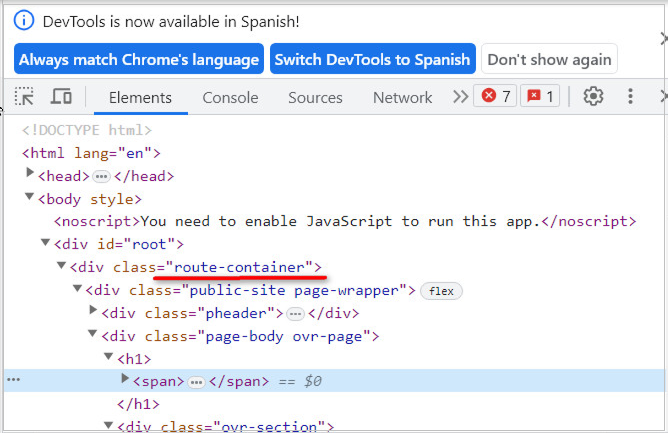
Y finalmente se cierra corchete ]
Tipos de XPath
Xpath absoluto:
- Más fácil de montar.
- Siempre va a ser único.
- Tienen un inconveniente. Si cambia algo en la página, por ejemplo, que incluyen otro elemento, es decir ponen otro div, pues ya nos son servirá ese xpath, que hemos copiado:
/html/body/form/div[2]/main/div[2]/div/div/div/div/div/div[1]/section[2]/map/area[2]
Xpath relativo:
- No pone el Xpath completo.
- Se refiere a alguna parte del Xpath.
- Más fácil que se mantenga si cambia algo en la página.
- Más complicado de montar.
Importante a la hora de montarlo:
- Primero, buscar la etiqueta más cercana a la que se quiere, que sea única.
- Buscar el elemento web más cercano al elemento deseado.
Como vemos a continuación en el ejemplo:
//*[@title="Europa"]
* el asterisco significa que quiere seleccionar todos los elementos. El asterisco solamente se pone en los elementos. En los tagname no se pone. Luego ponemos el elemento referenciado con la arroba y luego el nombre del elemento.
Luego tenemos:
contains() -> es útil cuando los elementos cambian dinámicamente. Cuando inicias sesión en una página web unas veces aparece una cosa y otras veces aparecen otras.
- busca un elemento con un texto parcial
Por ejemplo:
Elemento:<a href="/Documents/PoliticasPrivacidad/Politica%20de%20Privacidad.%20RGPD%20v4.pdf" title="Se abre en ventana nueva: Información Protección de Datos" target="_blank"> Información Protección de Datos <img src="/Style%20Library/PC/Img/icons/icon-external-link.svg" alt="Se abre en ventana nueva" class="icon-external-link noLazy"></a>
en este elemento, lo que hace es abrir un PDF donde hay una ley determinada (en este caso el reglamento de protección de datos, la versión cuatro). Pero lo mismo, la semana que viene hay otra versión, la 5, entonces no te serviría poner aquí el nombre completo, por eso utilizamos contains, para poner una parte del nombre completo, algo que no vaya a cambiar. Y así el diagrama nos seguirá valiendo en las siguientes versiones y nos llevará al mismo lugar. El contains siempre va con los elementos, siempre se refiere también a elementos.
Con el contains no se pone el signo = porque el href no es igual.
Se pone:
Xpath: //a[contains(@href,"RGPD")]
Contains, y entre paréntesis, @, el nombre del elemento, coma y el valor parcial, ósea el que contiene.
Después tenemos el text. Se refiere también a un elemento. Es el único caso que al referirse a un elemento no se le pone la @.
text() -> busca el texto del elemento.
no se le pone la @ aunque se refiera a un elemento.
Ejemplo:
Elemento: <label for="ctl00_ctl54_ctl07_txtSearch" class="hide"> Buscador </label>
Xpath: //label[contains(text()="Buscador")]
También podríamos ponerlo así:
Xpath: //label[(text()=" Buscador ")]
Quitando el contains y añadiendo un espacio delante y detrás del texto, en este caso Buscador.
Xpath: //label[(text()=" Buscador ")]
Y si pusiéramos la función normalize-space, entre paréntesis, antes del texto, ya da igual los espacios en blanco que haya antes y después de Buscador.
Xpath: //label[normalize-space(text()=" Buscador ")]
Tenemos también and. Que funciona igual que en JavaScript. Es cuando hay dos condiciones que queremos que se cumplan.
and -> para concatenar dos condiciones, las dos tienen que ser true.
Ejemplo:
Elemento: <a href="/es/Ministerio/Paginas/Secretaria-de-Estado-para-la-Union-Europea.aspx"> Secretaría de Estado para la Unión Europea </a>
Xpath: //a[contains(@href,"Secretaria-de-Estado") and contains(text(),"para la Unión Europea")]
Cuando queremos que se cumpla solamente una de las dos partes de la condición, utilizamos
Or la primera o la segunda condición tiene que ser true
Ejemplo:
Tenemos una página en español. Pero si el navegador en cualquier momento lo cambio al inglés, y quiero que me siga funcionando este xpath, utilizo un or.
Elemento en español:
<label for="ctl00_ctl54_ctl07_txtSearch" class="hide"> Buscador </label>
Elemento en inglés:
<label for="ctl00_ctl54_ctl07_txtSearch" class="hide"> Searcher </label>
Xpath: //label[contains(text(),"Searcher") or (contains(text(),"Buscador"))]
XPath con variables
En TAST tambien se le pueden poner variables a los Xpath:
//*[@title=”Europa”]
‘//*[@title=”’ + #continente + ‘”]’
No Comments